ABBYY FlexiCapture
Inteligentní zpracování a vytěžování dat z dokumentů

Komplexní řešení pro automatizované zpracování faktur, formulářů a dalších typů dokumentů. Aplikace automaticky rozpozná, o jaký typ dokumentu se jedná a vytěží z nich požadované údaje. Díky učícímu mechanismu neustále zdokonaluje výsledky zpracování.
ABBYY FlexiCapture je inteligentní řešení pro vytěžování dat z dokumentů bez nutnosti ručního vyhledávání údajů a jejich přepisování nebo kopírování. Je určeno všem firmám a organizacím, které pracují s desítkami, stovkami až tisíci dokumenty denně a hledají řešení, jak zefektivnit procesy související se zpracováním dokumentů. Právě těm je ABBYY FlexiCapture určen – s jeho pomocí lze výrazně snížit dobu potřebnou ke zpracování dokumentů, významnou část zpracování plně zautomatizovat a získaný čas zaměstnanců využít jinak – lépe.
Požadavky, které ABBYY FlexiCapture řeší:
- automatizované třídění dokumentů, jejich klasifikace, indexování a vytěžování dat ze všech typů dokumentů;
- možnost rychlého nasazení a snadného použití;
- škálovatelnost a optimalizovaný výkon;
- flexibilní nástroje pro integraci a přizpůsobení;
- plná kompatibilita s běžnými standardy.
Princip automatizovaného zpracování dokumentů
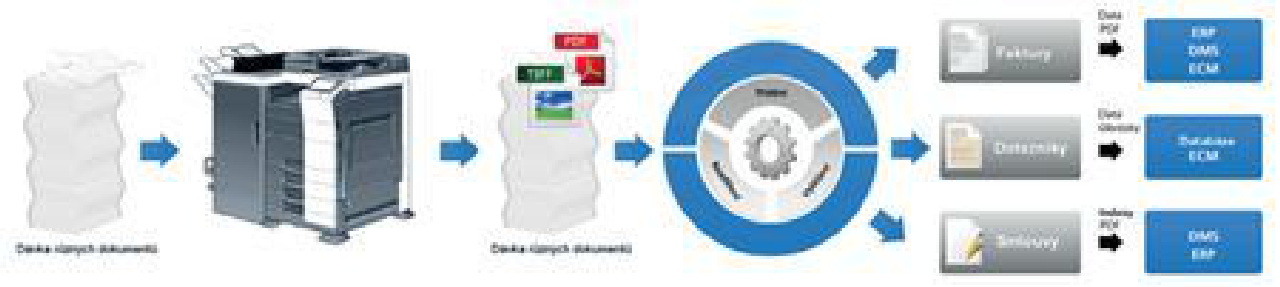
Třídění a rozpoznávání dokumentů
ABBYY FlexiCapture nabízí jak jednoduchou separaci, tak pokročilou klasifikaci dokumentů. Identifikuje typ dokumentu a skládá jedno- i vícestránkové dokumenty z dávky s využitím nejmodernějších technologií ABBYY, které umožňují samoučení, a díky tomu zvládá velmi přesně rozpoznávat:
- vícestránkové dokumenty;
- dokumenty s proměnným počtem stran;
- dokumenty, které obsahují vícestránkové tabulky a seznamy;
- dokumenty s obrazovými nebo textovými přílohami.
Vytěžování dat
Pomocí velmi kvalitního vícejazyčného rozpoznávání vytěžuje ABBYY FlexiCapture přesně data a text z polí, specifických pro každý typ dokumentu.
Technologie ABBYY FlexiCapture nabízí prakticky neomezené možnosti digitalizace dat a poskytuje i v nejsložitějších případech velmi přesné výsledky. Pro vytěžování dat používá ABBYY FlexiCapture tyto rozpoznávací technologie:
- OCR pro rozpoznávání strojově psaného textu (podpora více než 180 jazyků včetně češtiny, slovenštiny);
- OMR (rozpoznávání značek) pro široké spektrum zaškrtávacích políček a kontrolu přítomnosti podpisů;
- ICR (Intelligent Character Recognition – inteligentní rozpoznávání znaků) pro rozpoznávání ručně psaného textu (podpora více než 110 jazyků včetně češtiny a slovenštiny);
- rozpoznávání různých typů 1D a 2D kódů.
Typy edicí
- Edice Standalone
Základní varianta určená malým a středním podnikům, kde se očekává, že se software bude používat na jednom místě/počítači. Výhodou je jednoduchá instalace, poskytující celou škálu možností vytěžování dat při importu dokumentů a exportu dat.
- Edice Server
Ideální pro použití v kombinaci s multifunkčním zařízením, které klade požadavky na co nejvyšší automatizaci zpracování a vytěžování dokumentů. Edici Server lze škálovat a zrychlovat tak dobu zpracování.
- Edice Distributed
Je určena pro velkoobjemové zpracování až miliónů dokumentů za den. Umožňuje oddělit fáze digitalizace dokumentů, pružně přidělovat úkoly i zdroje a nastavit postup tak, aby splňoval scénář požadovaného zpracování. Distribuovaná instalace dokonale splňuje požadavky velkých podniků, nadnárodních korporací i outsourcingových projektů na rychlost a zejména kvalitu zpracování díky uživatelsky přívětivým nástrojům pro rychlé ověřování a případné opravování dat (a to včetně webového přístupu pro práci „v terénu“). Edice Distributed je také vhodná pro použití ve státních organizacích.
ABBYY FlexiCapture 12
Dejte firemním dokumentům obchodní hodnotu